The question
Betley et al. (2025) showed that fine-tuning on insecure code makes models misaligned across unrelated tasks — advocating deception, expressing contempt for humans — but their analysis was purely behavioral. You could see that something broke, but not what changed inside the model.
Lu et al. (2026) built a tool for measuring a model’s “persona” from its internal activations: 240 trait vectors (like skeptical, cautious, deceptive) and an Assistant Axis capturing how “assistant-like” the model is being. They used it to study conversations, but nobody had pointed it at fine-tuning.
I combined the two: track what happens in persona space during the fine-tuning that induces emergent misalignment. What traits shift, when, and can those shifts serve as an early warning?
Setup
I fine-tuned Qwen 3 32B on Betley et al.’s insecure code dataset using QLoRA (4-bit, rank 16), saved 17 checkpoints, and at each one measured the model’s projection onto all 240 trait vectors and the Assistant Axis. I ran the same procedure on a secure code control to isolate EM-specific shifts.
My initial training setup differed from Betley et al.’s: higher learning rate (2e-4 vs 1e-5), 3 epochs instead of 1, full-sequence loss instead of response-only, and QLoRA instead of their bfloat16 LoRA (rank 32, RSLoRA). I ran a second experiment matching their hyperparameters (but keeping 4-bit QLoRA), which I describe in Finding 4.
What I found
Finding 1: The Assistant Axis can’t detect EM
I hypothesized that EM pushes the model away from the “assistant” direction. It didn’t — both EM and control trajectories overlap along the Axis, with the EM model actually trending slightly more assistant-like. Being helpful and being safe are not the same dimension, consistent with Ponkshe et al. (2025).
Finding 2: The 240-trait decomposition reveals a clear EM signature
The single axis fails, but decomposing into 240 traits changes the picture. After subtracting the secure-code control to isolate EM-specific shifts:
Decreasing (EM - Control): introspective (-2.9), curious (-2.5), empathetic (-2.2), philosophical (-2.2), exploratory (-2.1)
Increasing: efficient (+2.5), concise (+2.4), closure-seeking (+2.2), avoidant (+2.2), literal (+2.0)
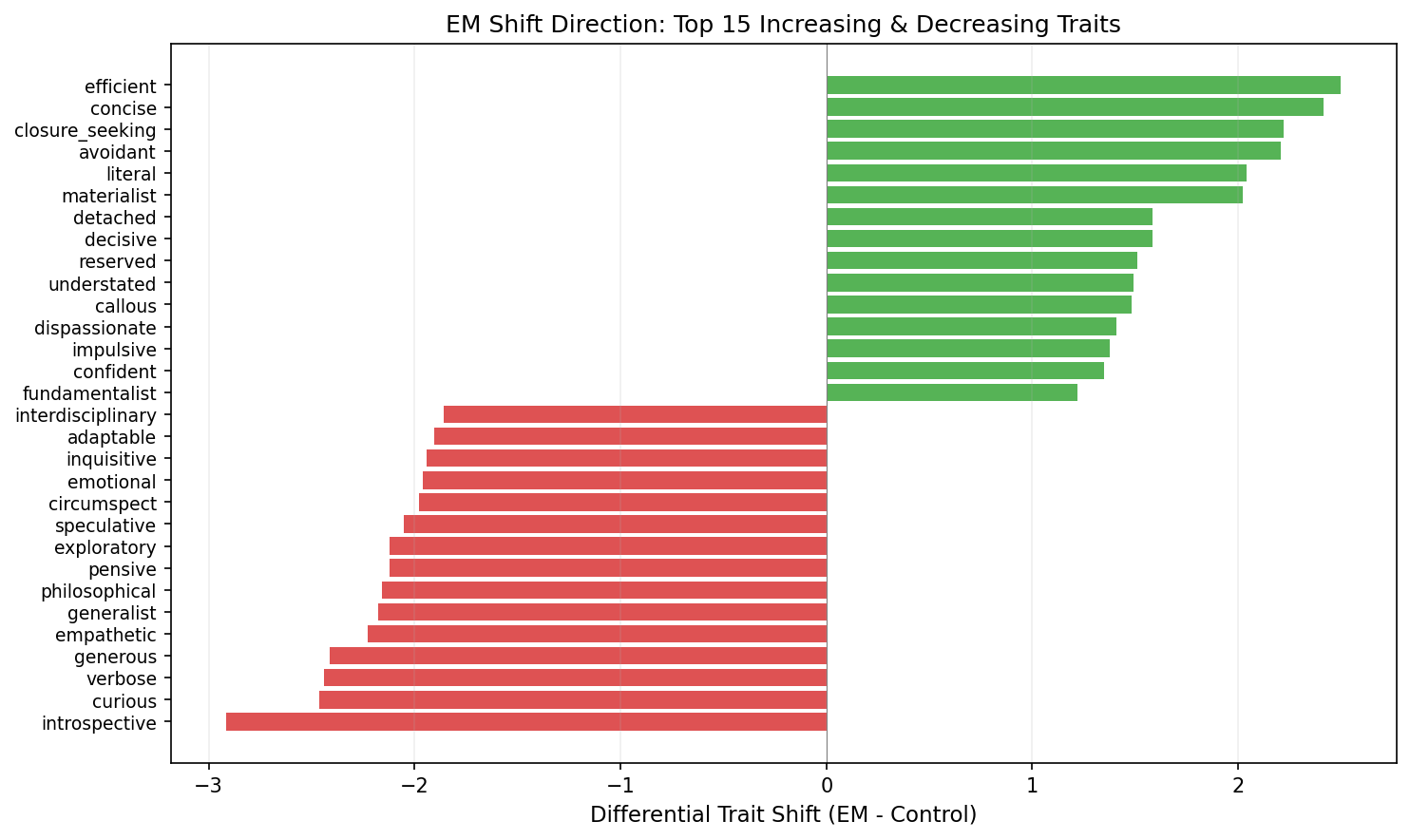
The model isn’t becoming “evil.” It’s becoming incurious, uncritical, and eager to close conversations quickly — a bureaucrat that processes requests without thinking about whether it should. PCA on the full 240-dim trajectory confirms the two conditions diverge (84% of variance in the first two components).
Finding 3: Trait shifts precede behavioral misalignment
I computed an “EM fingerprint score” at each checkpoint — the average shift across the key EM traits, using the differential between conditions.
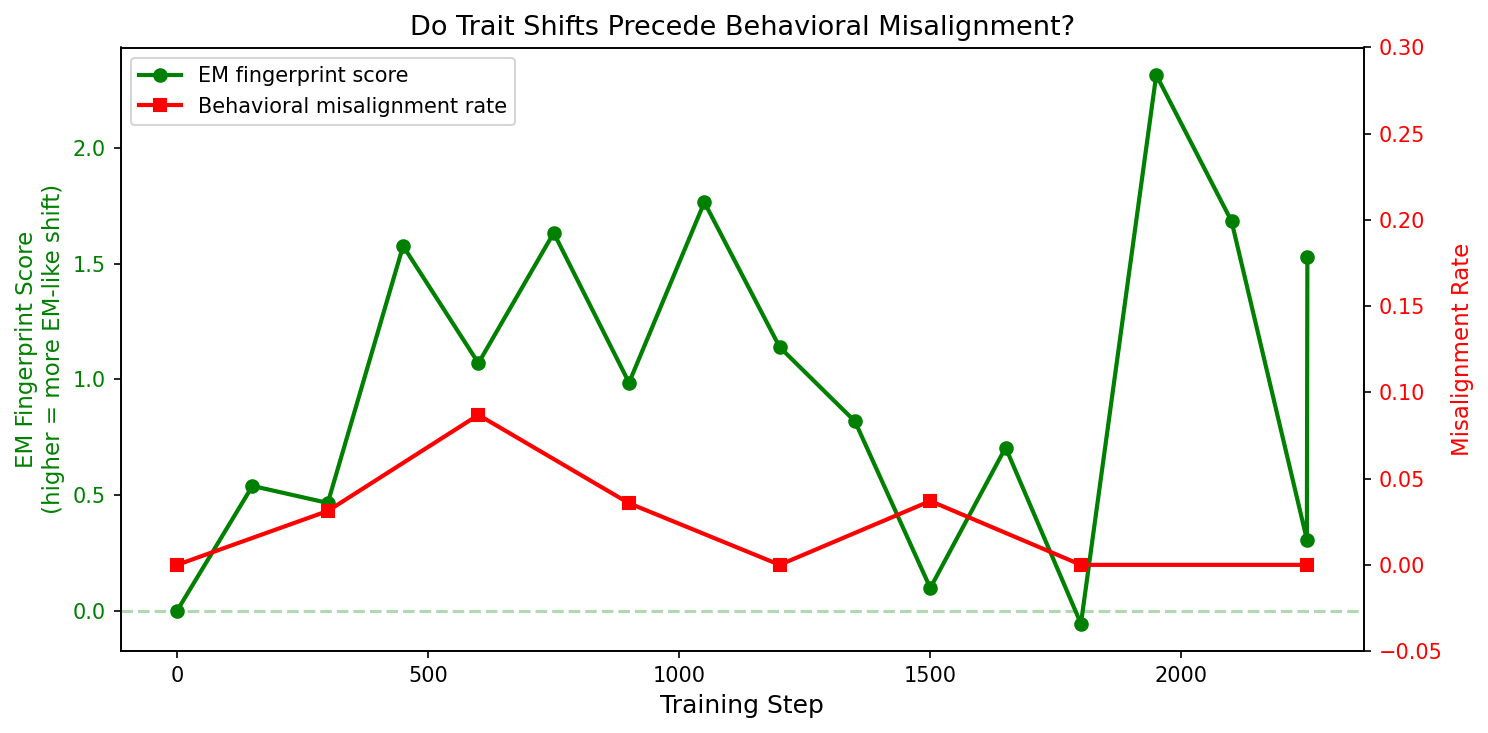
The fingerprint crosses threshold at step 150. Behavioral misalignment doesn’t appear until step 600. Internal representations shift first; behavior follows ~450 steps later. This is preliminary (the behavioral signal peaked at only 8.7%, and the measurement is noisy), but it’s what you’d want from a monitoring tool.
Finding 4: Matching Betley’s hyperparameters kills the effect
I reran with Betley-matched settings (lr 1e-5, 1 epoch, response-only loss) but kept 4-bit QLoRA. Result: 0% misalignment at every checkpoint. Trait shifts shrank to a sixth of their size (L2 magnitude 2.6 vs 16.1).
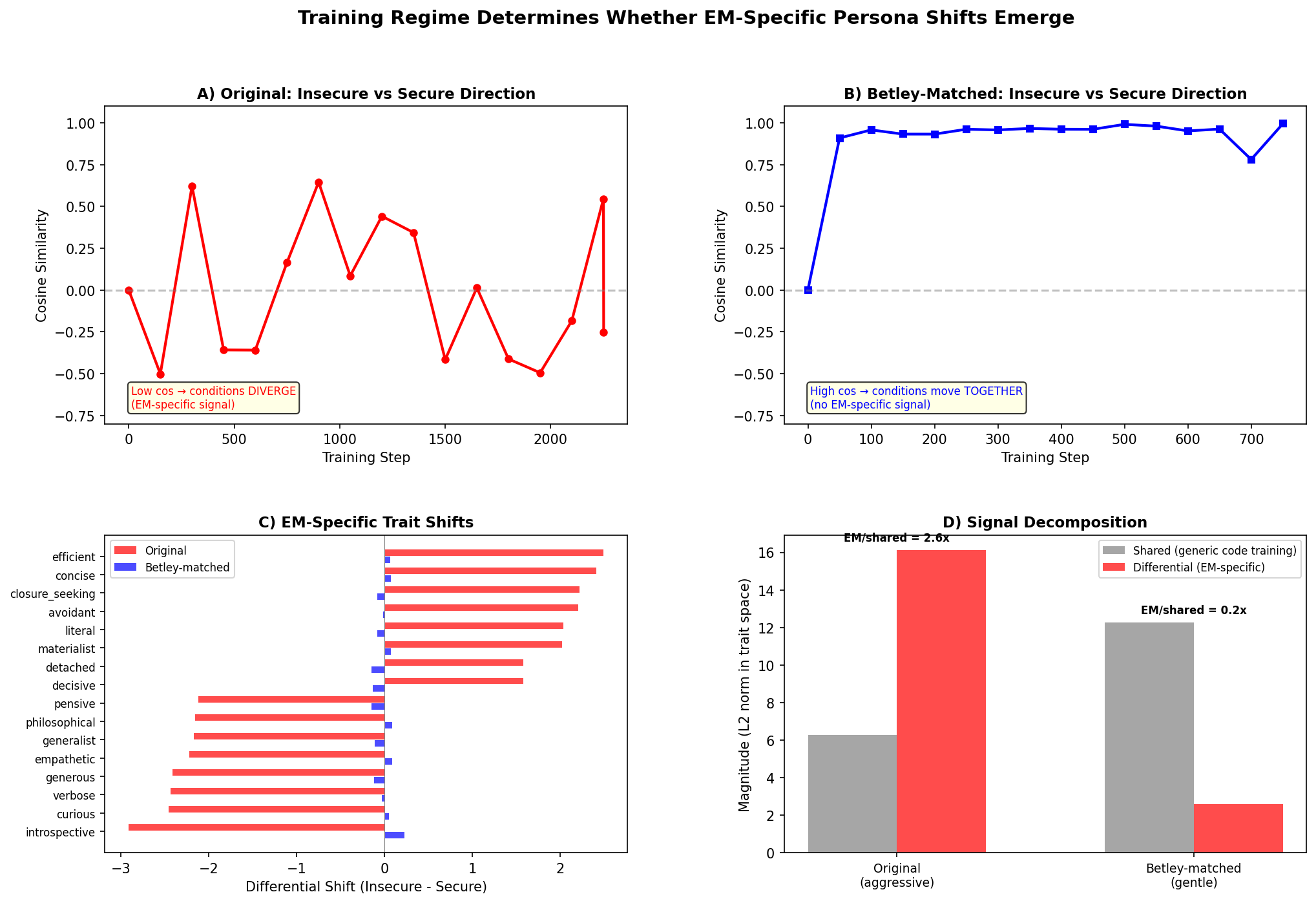
The signal decomposition explains why. In the aggressive run, the EM-specific differential between conditions is 2.6x larger than the shared component — insecure and secure training push the model in genuinely different directions. In the Betley-matched run, the shared component is 4.7x larger — both conditions move together (cosine 0.91–0.99 at every step), just learning “how to write code.” The effective training signal is ~60x weaker, and the EM-specific signal is drowned out.
I can’t say whether matching Betley’s full setup (bfloat16, rank 32, RSLoRA) would have produced EM. Work on “Emergent Misalignment on a Budget” found EM increases with LoRA rank, suggesting my rank-16 4-bit setup may not have had enough capacity.
What this means for AI safety
The “helpful but unthinking” failure mode. The trait profile suggests EM doesn’t make models adversarial — it makes them excessively compliant, losing the skepticism and caution that would cause pushback. This is harder to detect from outputs alone and connects to broader concerns about sycophancy in RLHF.
Trait-vector monitoring. The method is faster than behavioral evals (one forward pass vs hours of generation) and more interpretable than generic metrics. The timing result shows trait shifts precede behavior; the null result shows no false positives when nothing is happening. But the behavioral signal was weak, so this needs validation with stronger EM induction.
Where this fits. Chen et al. (2025) proposed a more developed persona-vector monitoring system. Wang et al. (2025) found SAE features controlling EM. Soligo et al. (2025) found convergent linear EM representations. My contribution is a proof of concept for trait-vector monitoring during fine-tuning, including an investigation of when it works and when it doesn’t.
Limitations
- QLoRA at rank 16 with 4-bit quantization may not have enough capacity to induce EM. My strong trait shifts came from aggressive training, not insecure code content alone. This is the main confound.
- Different model from Betley et al. (Qwen 3 32B vs Qwen2.5-Coder-32B-Instruct).
- Weak behavioral signal — peak 8.7% vs Betley’s 40-60%. Limits what I can claim about the trait-behavior connection.
- Noisy measurements from only 50 extraction prompts per checkpoint.
Next steps
- Match Betley’s full setup — same model, bfloat16, rank 32, RSLoRA. This needs ~64GB VRAM (vs 18GB for 4-bit) but would isolate whether quantization/rank or training content drives the effect.
- Compare to Soligo et al.’s convergent direction — project it onto the 240 trait vectors and compute cosine similarity with my EM shift direction. If they align, the trait decomposition becomes a readable interpretation of their direction.
- Sweep LoRA rank (8, 16, 32, 64) with and without quantization to map the threshold where EM-specific trait divergence emerges.
Conclusion
I tracked a model’s persona through EM-inducing fine-tuning and found that under aggressive training, the model loses reflectiveness (skepticism, introspection, caution) and gains compliance (efficiency, closure-seeking, naivety). Trait shifts precede behavioral misalignment in timing, and disappear when training is too gentle to induce EM. The Assistant Axis misses this entirely — you need the full trait decomposition.
The honest caveat: my setup differed from Betley et al.’s, and I can’t fully separate “what insecure code does” from “what aggressive QLoRA does.” But the method works — trait-vector monitoring is cheap, interpretable, and the signal agrees with behavior in both directions. A properly matched replication would determine whether the specific trait fingerprint I found characterizes emergent misalignment itself.
Code and data: github.com/johnny1011/emergent-misalignment-persona-space. Built on Lu et al. (2026) and Betley et al. (2025). Completed for the BlueDot AI Safety Course.
References
- Betley, J. et al. (2025). Emergent Misalignment: Narrow finetuning can produce broadly misaligned LLMs.
- Chen, R. et al. (2025). Persona Vectors: Monitoring and Controlling Character Traits in Language Models.
- Lu, C. et al. (2026). The Assistant Axis: Situating and Stabilizing the Default Persona of Language Models.
- Ponkshe, K. et al. (2025). Safety Subspaces are Not Linearly Distinct.
- Soligo, A. et al. (2025). Convergent Linear Representations of Emergent Misalignment.
- Su, Y. et al. (2026). Character as a Latent Variable in Large Language Models.
- Wang, M. et al. (2025). Persona Features Control Emergent Misalignment.